About me
I am currently a staff algorithm engineer of Ant Group, leading a team of over ten individuals for research and development in multi-modal LLMs. My main interest is to design and deliver cognitive computing services, including computer vision, visual language alignment and multimodal video understanding. I have published 30+ papers in top-tier conferences and journals, including CVPR/ICML/SIGIR/ECCV/IJCAI/AAAI.
I am currently looking for full-time algorithm engineers and research interns. Please contact me (qingpei.gqp@antgroup.com) with your CV if you are interested!
🔥 News
-
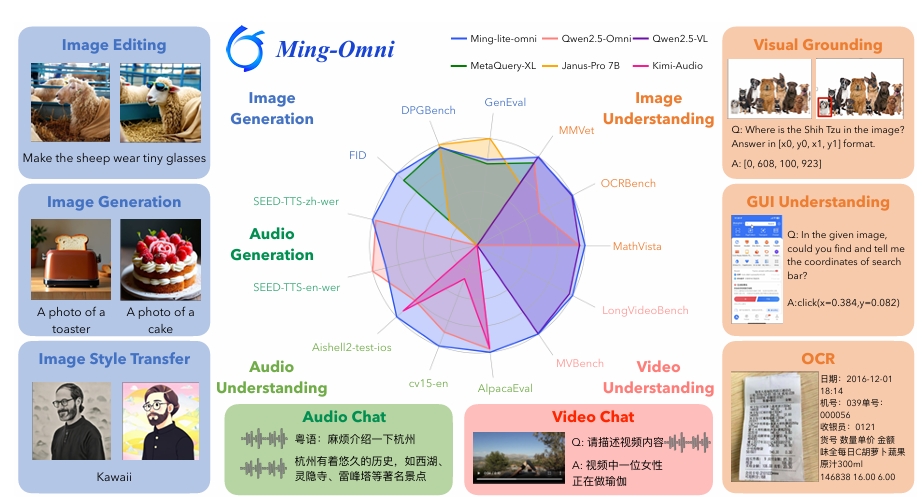
2025.05: 🎉🎉 We proposed Ming-Omni | [
], a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation.
-
2025.06: 🎉🎉 3 papers are accepted by ICCV 2025!
📝 Selected Publications
(Out of 30+ publications)
🧠 Omni LLMs
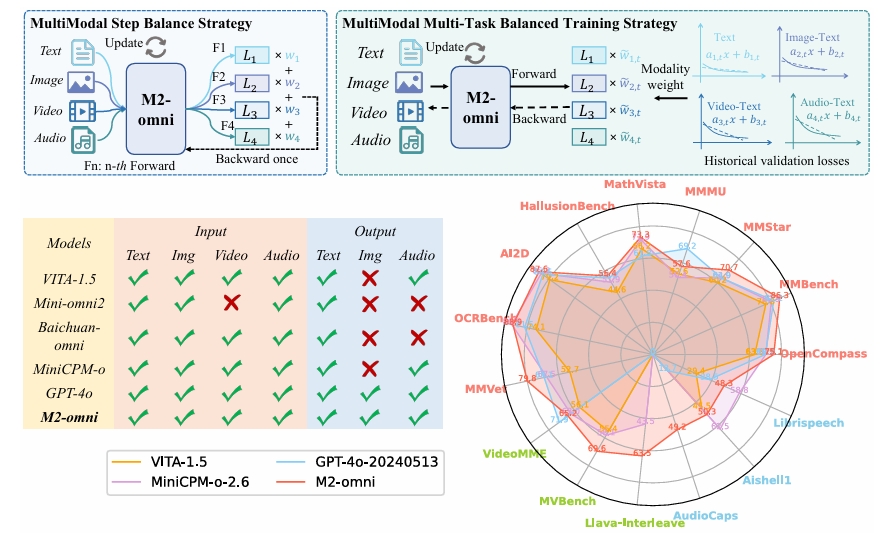
M2-omni: Advancing omni-mllm for comprehensive modality support with competitive performance
Qingpei Guo, Kaiyou Song, Zipeng Feng, Ziping Ma, Qinglong Zhang, Sirui Gao, Xuzheng Yu, Yunxiao Sun, Tai-Wei Chang, Jingdong Chen, Ming Yang, Jun Zhou
📸 Multimodal LLMs
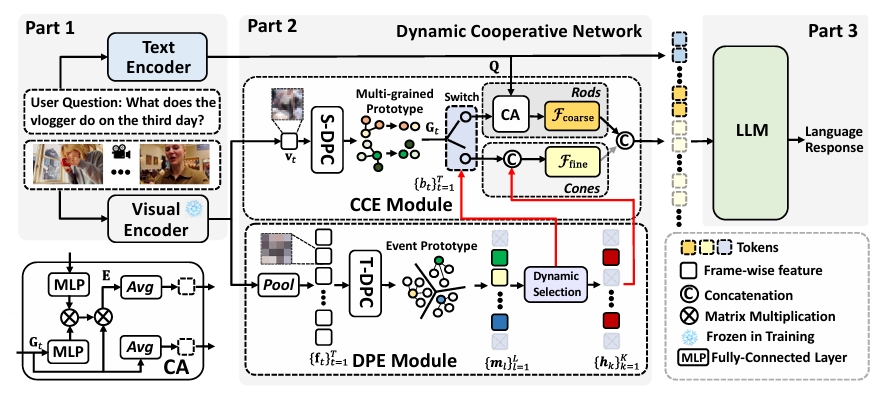
DynFocus: Dynamic Cooperative Network Empowers LLMs with Video Understanding
Yudong Han, Qingpei Guo*, Liyuan Pan, Liu Liu, Yu Guan, Ming Yang
Corresponding author
Code |

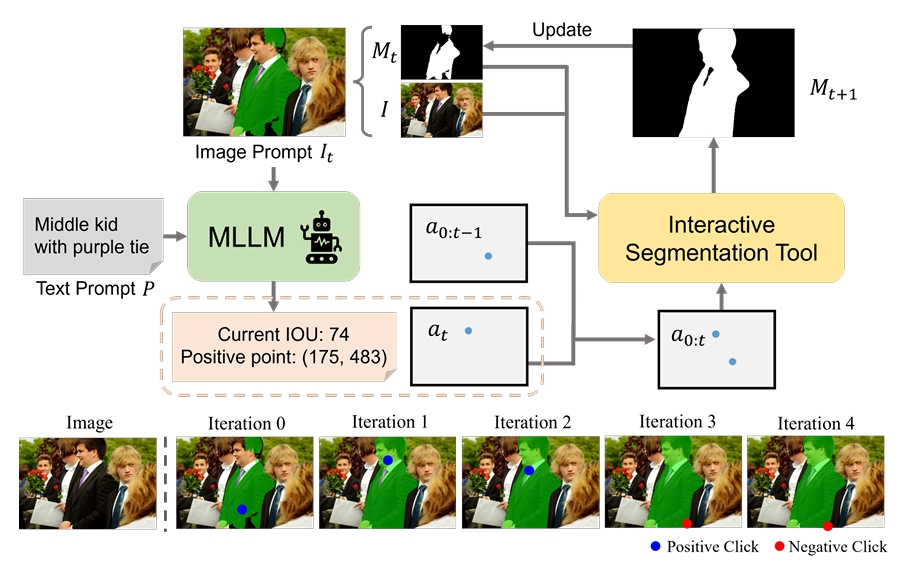
Muzhi Zhu, Yuzhuo Tian, Hao Chen, Chunluan Zhou, Qingpei Guo*, Yang Liu, Ming Yang, Chunhua Shen
Corresponding author
Code |

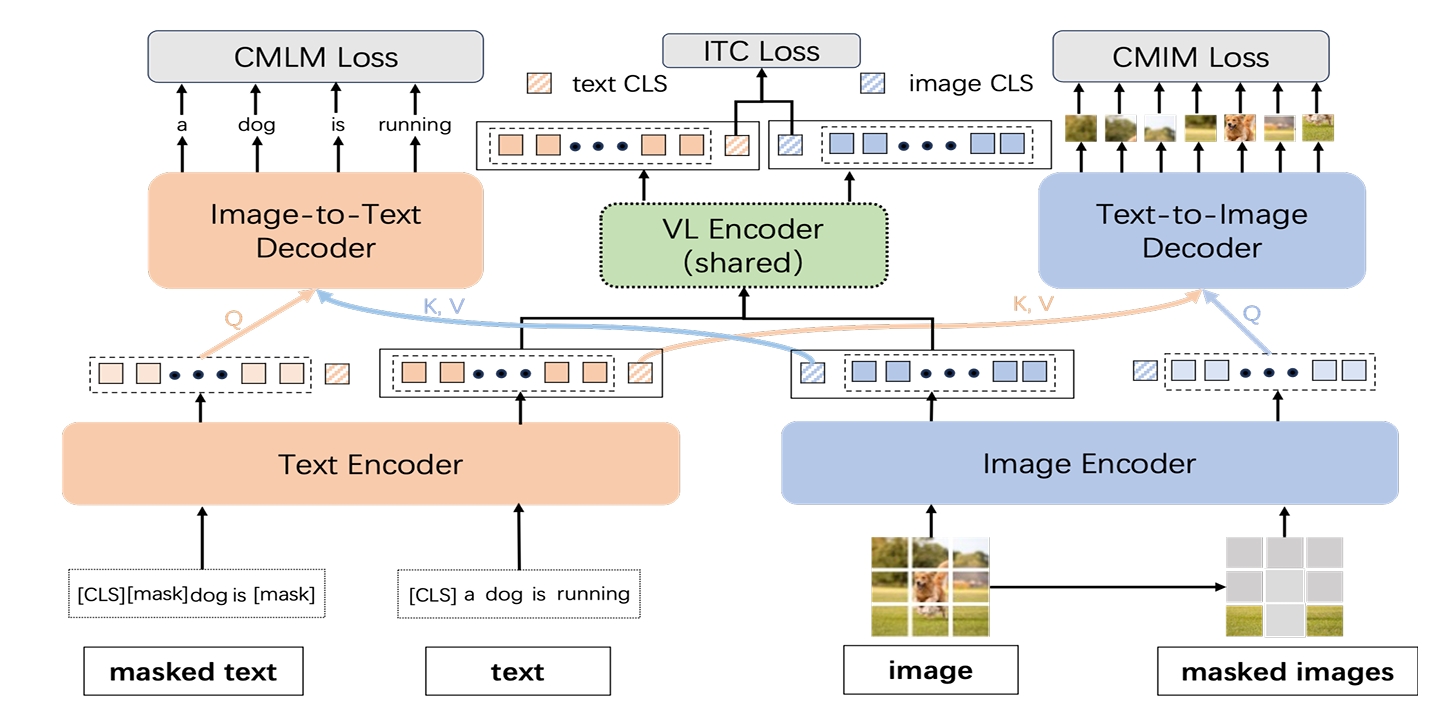
M2-Encoder: Advancing Bilingual Image-Text Understanding by Large-scale Efficient Pretraining
Qingpei Guo, Furong Xu, Hanxiao Zhang, Wang Ren, Ziping Ma, Lin Ju, Jian Wang, Jingdong Chen, Ming Yang
 |
|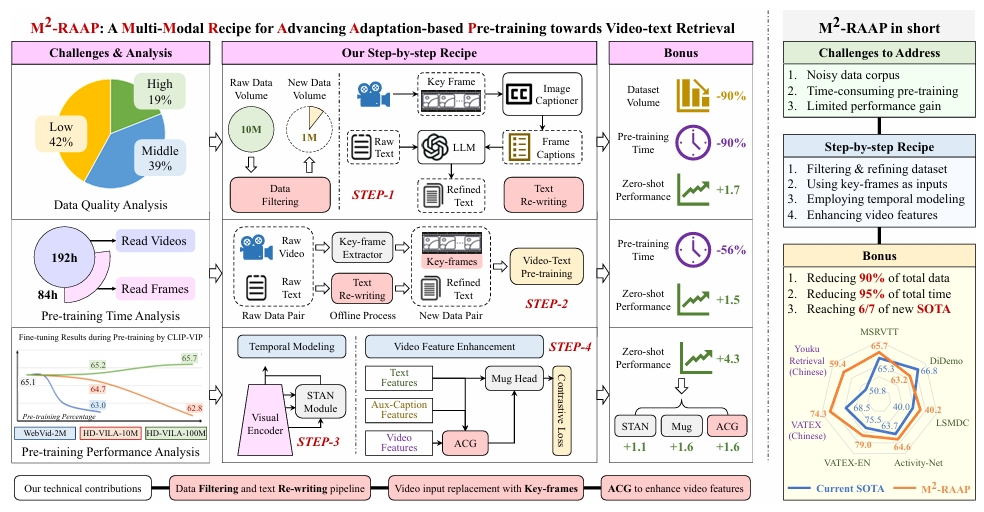
XingningDong, ZipengFeng, ChunluanZhou, XuzhengYu, MingYang, Qingpei Guo*
Corresponding author
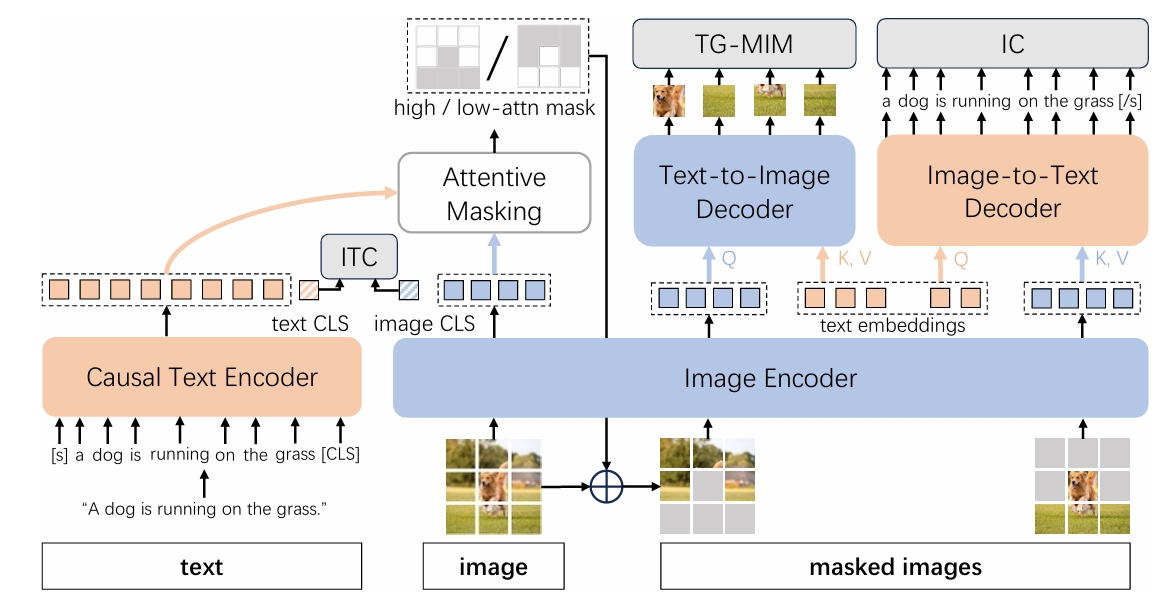
SyCoCa: Symmetrizing Contrastive Captioners with Attentive Masking for Multimodal Alignment
Ziping Ma, Furong Xu, Jian Liu, Ming Yang, Qingpei Guo*
Corresponding author
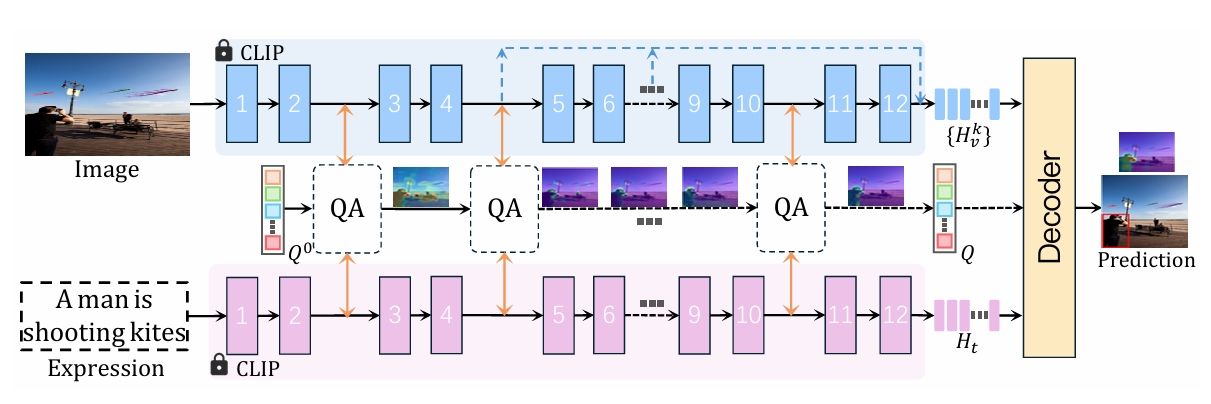
Referencing Where to Focus: Improving Visual Grounding with Referential Query
Yabing Wang, Zhuotao Tian, Qingpei Guo, Zheng Qin, Sanping Zhou, Ming Yang, Le Wang
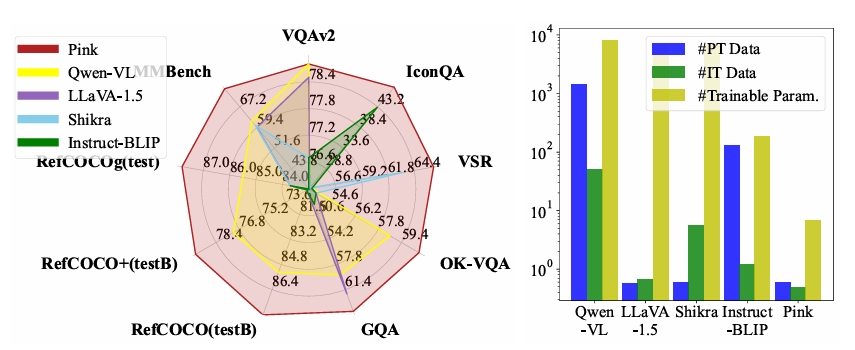
Pink: Unveiling the Power of Referential Comprehension for Multi-modal LLMs
Shiyu Xuan, Qingpei Guo, Ming Yang, Shiliang Zhang
Code|

🛠️ Application of MLLMs
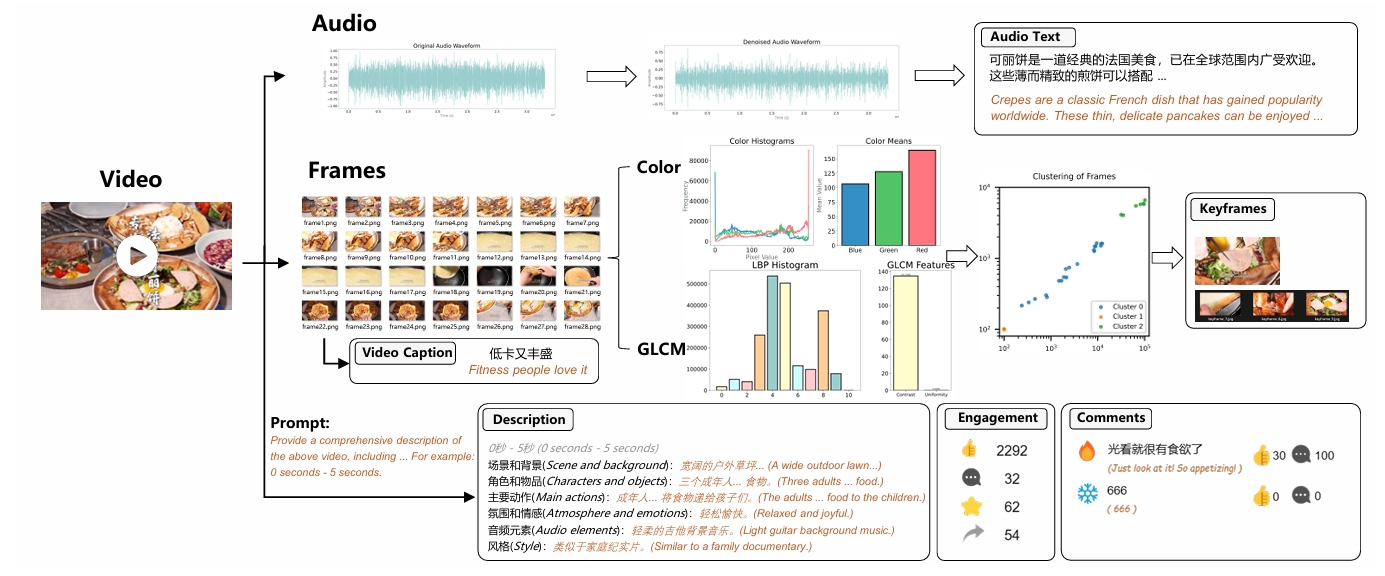
HOTVCOM: Generating buzzworthy comments for videos
Yuyan Chen, Yiwen Qian, Songzhou Yan, Jiyuan Jia, Zhixu Li, Yanghua Xiao, Xiaobo Li, Aaron Xuxiang Tian, Ming Yang, Qingpei Guo*
Corresponding author
💬 Invited Talks
- 2024.07, My speech about our model Ming-Omni.
📌 Patents
US Patents
Guo Q, Chu W. Coding apparatuses, and data processing methods and apparatuses: U.S. Patent Application 18/348,122[P]. 2024-4-25.
Guo Q. Method and system for facilitating recognition of vehicle parts based on a neural network: U.S. Patent 11,475,660[P]. 2022-10-18
Others
一种鲁棒的基于深度学习的连续情绪跟踪方法-CN106919903B
图像处理的方法及装置-CN111524150B
用于训练特征提取模型的方法、特征提取方法和装置- CN116522142A
基于自然交互的隐式身份认证方法-CN106888204B
用于确定文本和视频之间的相似度的方法和装置-CN116958868A
基于图片的意图检测方法及装置-CN115512340A
通过计算机执行的、用于识别车辆部件的方法及装置-CN110705590B
视频特征模型训练方法及装置、视频特征提取方法及装置-CN116721375A
一种通过多图形处理器计算对比损失的方法和装置-CN117556273A
一种聊天机器人应答方法和装置-CN110457456A
一种多模态模型的训练方法及装置-CN117541894A
训练内容理解模型和内容生成模型的方法及装置-CN117235534A
视频编辑方法及装置-CN117315056A
用于确定文本和视频之间的相似度的方法和装置-CN117556276A
大模型的训练方法和装置-CN117521759A
一种获取多模态特征方法和装置-CN117521017A
编码装置、数据处理方法及装置-CN115062782A
透過電腦執行的、用於車輛零件識別的神經網路系統、透過神經網路系統進行車輛零件識別的方法、進行車輛零件識別的裝置和計算設備-TWI742382B
📖 Educations
- 2014 - 2017, Master of Computer Applied Technology Institute of Software, Chinese Academy of Sciences.
- 2010 - 2014, Bachelor of Telecommunications Engineering Huazhong University of Science and Technology
- 2010 - 2014, Bachelor of Business Management (Dual Degrees) Huazhong University of Science and Technology
🎖 Fellowships and Awards
- Master Enterprise Supervisor of Chinese Academy of Sciences the Enterprise mentor.
- Master Enterprise Supervisor of Fudan University.
- The first place of ICDAR MLT Text Localization.
- Third place in ICCV COCO Panoptic Segmentation Challenge.
- Project Li Pei Bao - Fully automated claims settlement without intervention for the first time.
- Project Ding Sun Bao - Shenzhen Fintech Innovation Award.
- Reviewer of TPAMI/ CVPR/ ICCV/ IJCAI/ ECCV/ ACL/ ACM MM/ CoLM.
- China National Scholarship.
- Extreme Ownership Award- Ant Group Annual Awards